

3·
2 months agoThat’s unfortunate :( I think you can still run it in QEMU, if you’re interested.

That’s unfortunate :( I think you can still run it in QEMU, if you’re interested.
I see your point. However, integrating Rust properly in the Linux kernel is an uphill battle. Redox OS is not at all close to being stable, but it showcases that you can build a Rust kernel from scratch, and integrate it into an OS that meets some of the requirements of a modern one. Of course, considering it a toy project and glancing over its potential doesn’t help with adoption. They even mention in their description that currently they can only support a community manager and a student developer with the current donations. When you compare that to the amount of money and developers involved in the Linux kernel, it’s insignificant.
I was not suggesting that the Rust For Linux devs jump ship, but it could be beneficial for the investors behind the project to look at alternatives. Heck, the Linux kernel started as a toy project itself. I believe that a team focused solely on such a Rust-only kernel could spearhead needed changes to reach something stable, as opposed to investing time and money into fighting established C developers to integrate a memory-safe language in the kernel fully.

I think it might be Magic Research 2? Nevermind, I couldn’t find that review on the Steam page, so it must be another game.
Good luck! You can try the huggingface-chat repo, or ollama with this web-ui. Both should be decent, as they have instructions to set up a docker container.
I believe the Llama 3 models are out there in a torrent somewhere, but I didn’t dig to find it. For the 70B model, you’ll probably need around 64GB of RAM available, but the 7B one should run fine with just 8GB. It will be somewhat slow though, compared to the ChatGPT experience. The self-attention mechanism can be parallelized, which is why you will see much better results on a GPU. According to some others that tested it, if you offload some stuff to RAM, you could see ~10-12 tokens per second on an RTX 3090 for certain 70B models. But more capable ones will be at less than 1 token per second, all depending on the context window you use.
If you don’t have a GPU available, just give the Phi-3 model a try :D If you quantize it to 4 bits, it can apparently get 12 tokens per second on an iPhone haha. It should play nice with pooling information from a search engine, or a vector database like milvus, qdrant or chroma.
What db2 already said. Microsoft just released Phi-3 mini, which could, allegedly, run locally on newer smartphones.
If I understood correctly, the Rabbit thingy just captures your information locally and then forwards it to their server. So, if you want more power, you could probably do the same by submitting the same info to a bigger open source model than Phi-3, like Llama 3, hosted on your homelab. I believe you can set it up with huggingface/gradio, which sort of provides an API that you could use.
That way, you don’t need a shitty orange box, and can always get the latest open source models with a few lines of code. There are plenty of open source frameworks in the works at the moment, and I believe that we’re not far off from having multi-modal LLMs running on homelab-level hardware (if you don’t mind a bit of lag).
How will you move to WhatsApp if everyone else uses iMessage? Europe has the same issue, but reversed. Everyone uses WhatsApp and can’t jump to Signal/Telegram because they’re not as popular.
I got NFS Most Wanted (2005) working in Wine, and was somewhat impressed how easy it was at the time. Game worked quite well, and would only crash once in a while with some cryptic errors that I don’t remember. Made me hopeful for the future of linux gaming :)

Click for longer opinion
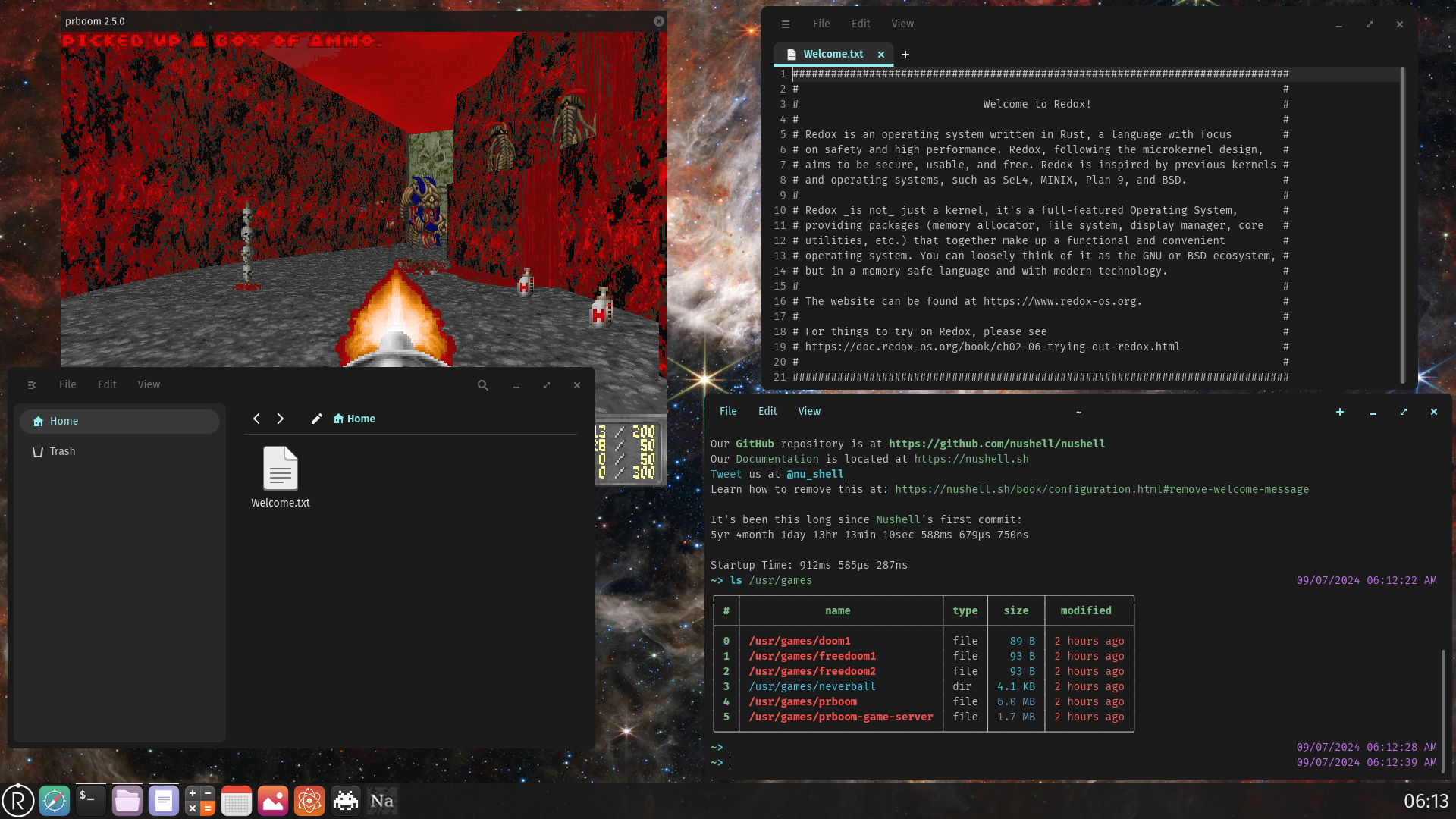
If I remember correctly, even though Fuchsia is used in production, it is mainly targetting mobile or IoT devices. Nevertheless, the underlying micro-kernel, Zircon, is written in C/C++, which differs from Redox. Now, I’m not saying that Redox solves everything by writing the kernel in Rust. It will require plenty
unsafeblocks to achieve what it needs, but it makes you aware beforehand that you should be careful about how you implement that bit of code. Having this clear marking could also make the kernel code review process more likely to catch issues.Disregarding this, if I am not mistaken, Redox aims to be a drop-in replacement for Linux one day, both for desktop and server, while Fuchsia only wishes to be integrated in/replace Android. Linux is perfectly fine for most use cases, I am not suggesting otherwise! However, given how many issues resulted from overflow/memory corruption issues that could have been potentially easier to identify if Rust (or any other memory safe language) was used, you’d think that there is incentive to rely on it for kernel development. Linus himself made this decision as well when allowing Rust to be used in the Linux kernel development (albeit perhaps a bit too early).
The Linux kernel is not flawed, and Redox is probably years away from being even near it. However, having memory-safety from the get-go as a requirement for developing the kernel could lead to fewer exploits, compared to what we have today with Linux. Just as you’ve said, most users are not aware of it/they don’t care, but the big players will care about keeping information safe on their servers. Just to conclude, Redox OS is not just Linux rewritten in Rust, and could potentially have many other benefits that are particularly juicy for data centers. Too bad it’s not production ready yet :D